Capítulo 5 Análisis de Datos
En este capítulo aplicaremos todos los conceptos, bibliotecas y funciones del capítulo anterior orientado a la aplicación. El primer paso es instalar la librería Tidyverse.
## ── Attaching packages ─────────────────────────────────────────────────────────────────── tidyverse 1.3.0 ──## ✓ ggplot2 3.3.2 ✓ purrr 0.3.3
## ✓ tibble 3.0.3 ✓ dplyr 1.0.1
## ✓ tidyr 1.1.1 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.5.0## ── Conflicts ────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()5.1 Importar base de datos.
Ahora demostraremos como cargar la data tanto para R-Studio de escritorio como para R-Studio Cloud (versión online).
5.1.1 Desde R-Studio de escritorio
Para importar bases de datos en formato Excel en R-Studio se ingresa en la ventana 2 en donde dice Import Dataset como se observa en la siguiente imagen.
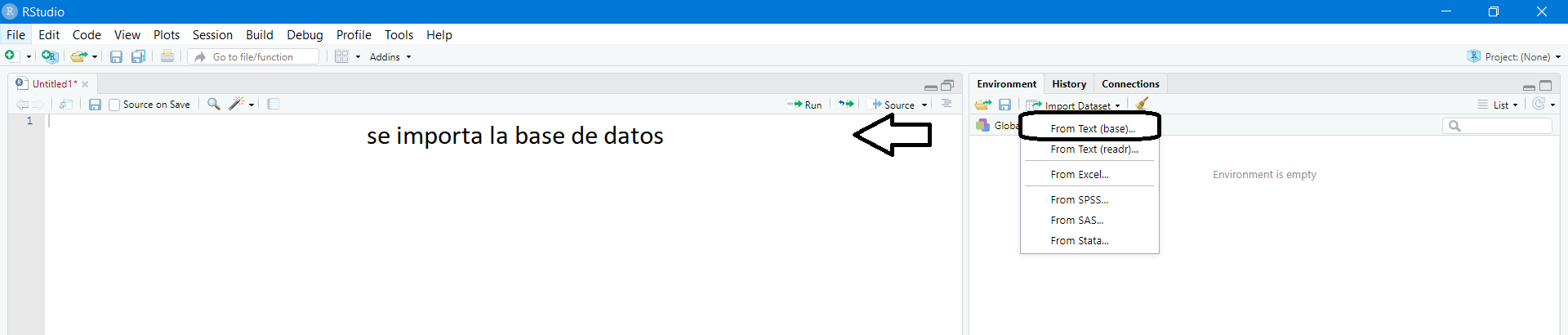
Figura 5.1: Importar base de datos desde R-Studio.
Luego aparece una ventana en donde buscamos nuestra base de datos en nuestro computador, y una vez seleccionado el archivo aparece una segunda ventana llamada Import Dataset como se muestra en las dos siguientes imágenes. En la primera es la forma correcta de subir la base de datos como se encuentra demarcado el Heading colocamos YES esto es con el fin de que la base de datos que subamos tenga el encabezado correspondiente como se encuentra demostrado en la imagen.
.PNG)
Figura 5.2: Importar base de data set.
De lo contrario se puede ver en la siguiente imagen lo que sucede si ponemos “NO” en donde el encabezado se muestra como una observación más.
.PNG)
Figura 5.3: Importar data set, parte 2.
Una vez importada la base de datos podemos ver que aparece como Data Frame en la ventana 2, en esta también nos muestra características básicas como la cantidad de observaciones que posee el Data Frame. También se puede observar en la consola que se importó el archivo correctamente, es recomendable copiar y pegar en el script lo demarcado, así cada vez que queramos trabajar se subirá automáticamente la base de datos.
.PNG)
Figura 5.4: Importar data set, parte 3.
5.1.2 Desde R-Studio Cloud
En cuanto a R-Studio Cloud se suben los archivos un poco diferentes, en este nos tenemos que dirigir la ventana 4 en donde dice Upload, esto abrirá una ventana llamada Target directory presionamos donde dice elegir archivo, con esto nos abre otra ventana en donde debemos buscar el archivo que queremos importar.

Figura 5.5: Importar desde R-cloud.
Esto creara un archivo en la ventana 4 como se muestra en la siguiente imagen. Y ahora se procede a realizar la importación del archivo en la segunda ventana como se realiza en R-Studio.
.PNG)
Figura 5.6: Importar desde R-cloud, parte 2.
5.2 Unir o combinar data frames en R
Cuando se trabaja con grandes cantidades de datos, a veces es necesario combinar bases de datos para consolidarlo en una que contenga toda la información. En este capítulo veremos diferente forma de realizar datos relacionales, pero primero hay que tener en cuenta la siguiente recomendación:
- Debes extraer los datos básicos de cada base de datos como:
- La cantidad de filas y columnas por cada base de datos.
- De qué tipo son las columnas, por ejemplo, si son numéricas o caracter.
- Revisar cuidadosamente la visualización de la base de datos para observar si existe algún punto en común entre las bases de datos.
- Debes conocer que representa cada variable de base de datos.
- Luego realiza un diagrama para ver las variables en común.
Como se observa en la siguiente imagen, tenemos la columna ID esta sería la llave para unir las diferentes bases de datos.
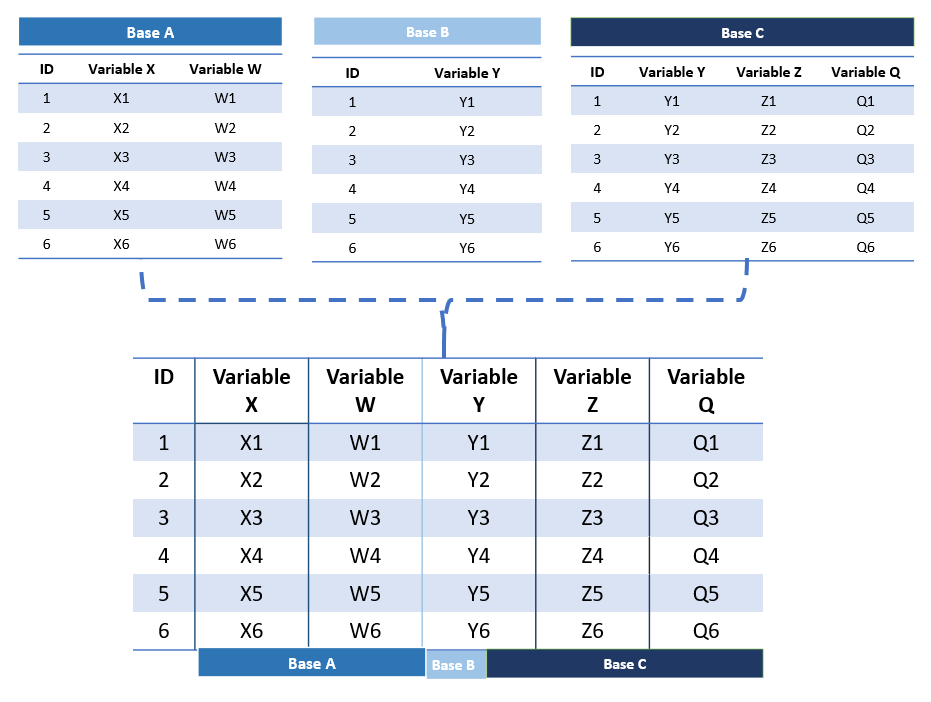
Figura 5.7: Combinar data frames en R.
En segundo lugar, hay que tener en cuenta las tres familias de verbos diseñados para trabajar con datos relacionales:
- filtering joins (Filtrado de combinaciones), que filtran las observaciones de un marco de datos en función de si coinciden o no con una observación de la otra tabla.
- set operations (Establecer operaciones), que tratan las observaciones como si fueran elementos establecidos.
- mutating joins (Uniones de trasformación), que agregan nuevas variables a un marco de datos a partir de observaciones coincidentes en otro.
5.2.1 Mutating joins (Uniones de trasformación)
Esta busca combinar variables a partir de dos tablas, en la que busca coincidencias de observaciones de acuerdo con su put y luego copia las variables de una tabla en la otra. Tal como mutate(), las funciones de unión agregan variables hacia la derecha, por lo que, si tienes muchas variables inicialmente, las nuevas variables no se imprimirán.
Una de las uniones más simples es a través de mage() para hacer cruces de tablas, como se muestra en la siguiente imagen.
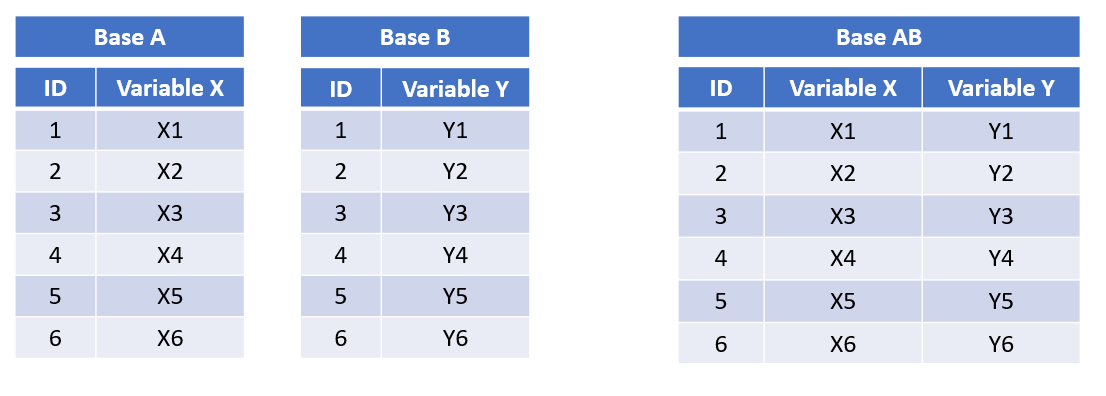
Figura 5.8: Ejemplo principal.
Para ello crearemos 2 bases baseA y baseB con una llave o columna en común ID.
#vectores
A <- c("x1", "x2", "x3", "x4", "x5", "x6")
ID <- c( 1, 2, 3, 4, 5, 6)
B <- c("y1", "y2", "y3", "y4", "y5", "y6")
# data frame
baseA <- data.frame(ID, A)
baseB <- data.frame(ID, B)## ID A
## 1 1 x1
## 2 2 x2
## 3 3 x3
## 4 4 x4
## 5 5 x5
## 6 6 x6## ID B
## 1 1 y1
## 2 2 y2
## 3 3 y3
## 4 4 y4
## 5 5 y5
## 6 6 y6Para unir la baseA y en la baseB utilizaremos merge() para crear la base AB.
## ID A B
## 1 1 x1 y1
## 2 2 x2 y2
## 3 3 x3 y3
## 4 4 x4 y4
## 5 5 x5 y5
## 6 6 x6 y65.2.1.1 Unión interior
La forma más simple de unión es la unión interior (del inglés inner join). Como se muestra en la siguiente imagen:
Pero primero crearemos 3 vectores ID, A y B para luego crear un baseA y baseB.
A continuación, en vez de crear un base llamada baseAB se concatena la baseA con la baseB para llamarse baseA.
## ID A B
## 1 1 x1 y1
## 2 2 x2 y2
## 3 3 x3 y3
## 4 4 x4 y4
## 5 5 x5 y5
## 6 6 x6 y6Como se observas se unieron las baseA y baseB, en una unión interior mantiene las observaciones que aparecen en ambas tablas.
5.2.1.2 Uniones exteriores
Una unión exterior mantiene las observaciones que aparecen en al menos una de las tablas. Existen tres tipos de uniones exteriores:
- Una unión izquierda
left_join()mantiene todas las observaciones en x.
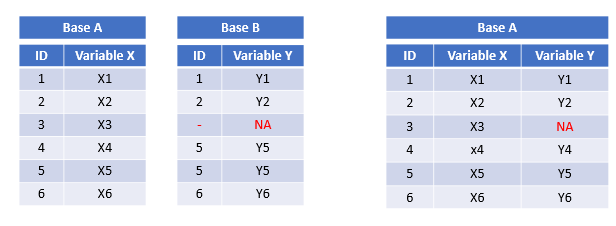
Figura 5.9: Ejemplo, left_join .
## ID A B
## 1 1 x1 y1
## 2 2 x2 y2
## 3 3 x3 <NA>
## 4 4 x4 y4
## 5 5 x5 y5
## 6 6 x6 y6- Una unión derecha
right_join()mantiene todas las observaciones en y.
.PNG)
Figura 5.10: Ejemplo, right_join .
## ID A B
## 1 1 x1 y1
## 2 2 x2 y2
## 3 3 x3 y3
## 4 5 x5 y5
## 5 6 x6 y6
## 6 4 <NA> y4- Una unión completa
full_join()mantiene todas las observaciones en x e y. observaciones en y.
.PNG)
Figura 5.11: Ejemplo, full_join .
## ID A B
## 1 1 x1 y1
## 2 2 x2 y2
## 3 4 x4 y4
## 4 5 x5 <NA>
## 5 6 x6 y6
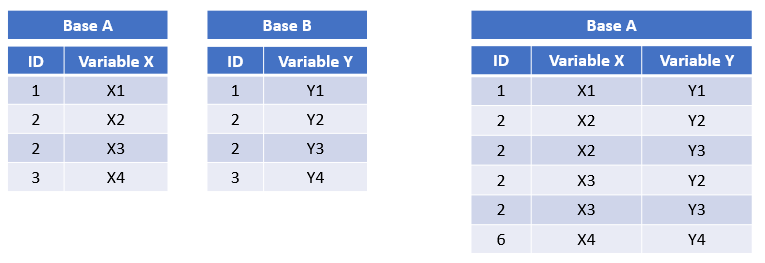
## 6 3 <NA> y35.2.1.3 claves (llave) duplicadas.
Pero que sucede si la ID esta duplicada ¿cómo podemos unirlas? para ellos nos pondremos en dos escenarios diferentes.
- El primero en tabla que tiene claves duplicadas. Esto es útil cuando quieres agregar información adicional dado que típicamente existe una relación “uno a muchos”.

Figura 5.12: Ejemplo, claves duplicadas.
## ID A B
## 1 1 x1 y1
## 2 2 x2 y2
## 3 1 x3 y1
## 4 2 x4 y2- Ambas tablas tienen claves duplicadas. Esto es usualmente un error debido a que en ninguna de las tablas las claves identifican de manera única una observación. Cuando unes claves duplicadas, se obtienen todas las posibles combinaciones, es decir, el producto cartesiano:
.PNG)
Figura 5.13: Ejemplo, claves duplicadas 2.
## ID A B
## 1 1 x1 y1
## 2 2 x2 y2
## 3 2 x2 y3
## 4 2 x3 y2
## 5 2 x3 y3
## 6 3 x4 y45.2.1.4 otras formas
| con dplyr | con merge |
|---|---|
inner_join(base1, base2) |
merge(base1, base2) |
full_join(base1, base2) |
merge(base1, base2, all.x = TRUE, all.y = TRUE) |
right_join(base1, base2) |
merge(base1, base2, all.y = TRUE) |
left_join(base1, base2) |
merge(base1, base2, all.x = TRUE) |
La ventaja de los verbos específicos de la libreria dplyr es que muestran de manera clara la intención del código: la diferencia entre las uniones es realmente importante, pero se esconde en los argumentos de merge(). Las uniones de dplyr son considerablemente más rápidas y no generan problemas con el orden de las filas.
Si las variables clave tiene diferente nombre (solo cosas en común)
merge(base1, base2, by.x="nombre variable base 1", by.y="nombre variable base 2")
Si la variable se llama igual en las dos bases (solo cosas en común)
merge(base1, base2, by="nombre variable")
Si queremos que se unan todos los casos
all=TRUE: merge(base1, base2, by="nombre variable", all=TRUE)
Si queremos unir por más de una variable: (si las variables se llaman igual en ambas bases)
merge(base1, base2, by=c("variable1", "variable2"))
Si las variables se llaman diferente en ambas bases
merge(base1, base2, by.x=c("variable1", "variable2"), by.y=c("variable1", "variable2"))
Otras formas efectivas de realizar una unión de base son los siguientes códigos.
5.2.2 Uniones de filtros
Las uniones de filtro unen observaciones de la misma forma que las uniones de transformación, pero afectan a las observaciones no a las variables. Existen dos tipos:
semi_join(x, y)mantiene todas las observaciones en x con coincidencias en y.
## Joining, by = "ID"## ID A
## 1 1 x1
## 2 2 x2
## 3 4 x4
## 4 5 x5anti_join(x, y)descarta todas las observaciones en x con coincidencias en y.
.PNG)
Figura 5.14: Ejemplo, anti_join.
## Joining, by = "ID"## ID A
## 1 3 x3Las semi uniones son útiles para unir tablas resumen previamente filtradas con las filas originales.
5.3 Exploración de la data
Ahora realizaremos una exploración de la base de datos, en este caso usaremos la base de datos disponibles llamado AB_NYC_2019.csv, que se encuentra disponible en el siguiente link:
https://www.kaggle.com/dgomonov/new-york-city-airbnb-open-data
Pero primero necesitamos la siguientes Liberia:
Importamos la base de datos a R-Studio como se vio en capítulos anteriores.
5.3.1 Inspección de una tabla
Luego realizamos la visualización de la data.
## Warning: package 'DT' was built under R version 3.6.2## Warning in instance$preRenderHook(instance): It seems your data is too big
## for client-side DataTables. You may consider server-side processing: https://
## rstudio.github.io/DT/server.htmlAhora realizaremos una breve descripción de las columnas de la data:
| Variable | Descripción |
|---|---|
| id | Código de hostal |
| name | Nombre de Airbnb |
| host_id | Código de Airbnb |
| host_name | Nombre del anfitrión |
| neighbourhood_group | Distritos de new york |
| neighbourhood | Vecindarios de los distritos |
| latitude | Coordenada latitud |
| longitude | Coordenada de longitud |
| room_type | Tipo de habitación |
| price | Precio |
| minimum_nights | Cantidad mínima de noches para una reserva |
| number_of_reviews | Numero de revisiones por mes |
| last_review | Ultimas reseña |
| reviews_per_month | Cantidad de comentarios por mes para la propiedad |
| calculated_host_listings_count | Numero de anuncios |
| availability_365 | Número de días en los que la lista está disponible para la reserva. |
Para obtener más información revisamos a través de los códigos como lo siguientes:
Queremos determinar si la base de datos posee algún problema usamos función problems().
## [1] row col expected actual
## <0 rows> (or 0-length row.names)Para ver la cantidad de observaciones usaremos la función nrow().
## [1] 48895Cuantas columnas o variables poseen la data con la función ncol().
## [1] 16si queremos ver las primeras observaciones usamos la función head().
## id name host_id host_name
## 1 2539 Clean & quiet apt home by the park 2787 John
## 2 2595 Skylit Midtown Castle 2845 Jennifer
## 3 3647 THE VILLAGE OF HARLEM....NEW YORK ! 4632 Elisabeth
## 4 3831 Cozy Entire Floor of Brownstone 4869 LisaRoxanne
## 5 5022 Entire Apt: Spacious Studio/Loft by central park 7192 Laura
## 6 5099 Large Cozy 1 BR Apartment In Midtown East 7322 Chris
## neighbourhood_group neighbourhood latitude longitude room_type price
## 1 Brooklyn Kensington 40.64749 -73.97237 Private room 149
## 2 Manhattan Midtown 40.75362 -73.98377 Entire home/apt 225
## 3 Manhattan Harlem 40.80902 -73.94190 Private room 150
## 4 Brooklyn Clinton Hill 40.68514 -73.95976 Entire home/apt 89
## 5 Manhattan East Harlem 40.79851 -73.94399 Entire home/apt 80
## 6 Manhattan Murray Hill 40.74767 -73.97500 Entire home/apt 200
## minimum_nights number_of_reviews last_review reviews_per_month
## 1 1 9 2018-10-19 0.21
## 2 1 45 2019-05-21 0.38
## 3 3 0 NA
## 4 1 270 2019-07-05 4.64
## 5 10 9 2018-11-19 0.10
## 6 3 74 2019-06-22 0.59
## calculated_host_listings_count availability_365
## 1 6 365
## 2 2 355
## 3 1 365
## 4 1 194
## 5 1 0
## 6 1 129## id name host_id
## 48890 36484363 QUIT PRIVATE HOUSE 107716952
## 48891 36484665 Charming one bedroom - newly renovated rowhouse 8232441
## 48892 36485057 Affordable room in Bushwick/East Williamsburg 6570630
## 48893 36485431 Sunny Studio at Historical Neighborhood 23492952
## 48894 36485609 43rd St. Time Square-cozy single bed 30985759
## 48895 36487245 Trendy duplex in the very heart of Hell's Kitchen 68119814
## host_name neighbourhood_group neighbourhood latitude longitude
## 48890 Michael Queens Jamaica 40.69137 -73.80844
## 48891 Sabrina Brooklyn Bedford-Stuyvesant 40.67853 -73.94995
## 48892 Marisol Brooklyn Bushwick 40.70184 -73.93317
## 48893 Ilgar & Aysel Manhattan Harlem 40.81475 -73.94867
## 48894 Taz Manhattan Hell's Kitchen 40.75751 -73.99112
## 48895 Christophe Manhattan Hell's Kitchen 40.76404 -73.98933
## room_type price minimum_nights number_of_reviews last_review
## 48890 Private room 65 1 0
## 48891 Private room 70 2 0
## 48892 Private room 40 4 0
## 48893 Entire home/apt 115 10 0
## 48894 Shared room 55 1 0
## 48895 Private room 90 7 0
## reviews_per_month calculated_host_listings_count availability_365
## 48890 NA 2 163
## 48891 NA 2 9
## 48892 NA 2 36
## 48893 NA 1 27
## 48894 NA 6 2
## 48895 NA 1 23Si queremos saber los nombres de las columnas o variables se usa la función colnames()
## [1] "id" "name"
## [3] "host_id" "host_name"
## [5] "neighbourhood_group" "neighbourhood"
## [7] "latitude" "longitude"
## [9] "room_type" "price"
## [11] "minimum_nights" "number_of_reviews"
## [13] "last_review" "reviews_per_month"
## [15] "calculated_host_listings_count" "availability_365"5.3.2 Selección de filas y columnas
A veces queremos trabajar con un subconjunto de la tabla, como por ejemplo una selección de filas y/o columnas. Para este tipo de selecciones se usa el corchete [].
## Warning in instance$preRenderHook(instance): It seems your data is too big
## for client-side DataTables. You may consider server-side processing: https://
## rstudio.github.io/DT/server.html## Warning in instance$preRenderHook(instance): It seems your data is too big
## for client-side DataTables. You may consider server-side processing: https://
## rstudio.github.io/DT/server.html## [1] 2539 2595 3647 3831si queremos extraer y operar sobre columnas individuales de una tabla se utiliza el signo $.
Ahora con la función str() veremos cómo están compuestas las columnas si son numéricas o factor, como también veremos la cantidad de variables y observaciones que posee la data.
## 'data.frame': 48895 obs. of 16 variables:
## $ id : int 2539 2595 3647 3831 5022 5099 5121 5178 5203 5238 ...
## $ name : Factor w/ 47906 levels ""," 1 Bed Apt in Utopic Williamsburg ",..: 12573 38016 45018 15591 19219 24849 8257 24896 15486 17573 ...
## $ host_id : int 2787 2845 4632 4869 7192 7322 7356 8967 7490 7549 ...
## $ host_name : Factor w/ 11453 levels ""," Valéria",..: 4997 4791 2913 6210 5929 1938 3549 9649 6880 1235 ...
## $ neighbourhood_group : Factor w/ 5 levels "Bronx","Brooklyn",..: 2 3 3 2 3 3 2 3 3 3 ...
## $ neighbourhood : Factor w/ 221 levels "Allerton","Arden Heights",..: 109 128 95 42 62 138 14 96 203 36 ...
## $ latitude : num 40.6 40.8 40.8 40.7 40.8 ...
## $ longitude : num -74 -74 -73.9 -74 -73.9 ...
## $ room_type : Factor w/ 3 levels "Entire home/apt",..: 2 1 2 1 1 1 2 2 2 1 ...
## $ price : int 149 225 150 89 80 200 60 79 79 150 ...
## $ minimum_nights : int 1 1 3 1 10 3 45 2 2 1 ...
## $ number_of_reviews : int 9 45 0 270 9 74 49 430 118 160 ...
## $ last_review : Factor w/ 1765 levels "","2011-03-28",..: 1503 1717 1 1762 1534 1749 1124 1751 1048 1736 ...
## $ reviews_per_month : num 0.21 0.38 NA 4.64 0.1 0.59 0.4 3.47 0.99 1.33 ...
## $ calculated_host_listings_count: int 6 2 1 1 1 1 1 1 1 4 ...
## $ availability_365 : int 365 355 365 194 0 129 0 220 0 188 ...Podemos observar a grandes rasgos que las variables room_type posee 3 niveles, que existe datos vacíos NA en la variable reviews_per_month y que neighbourhood posee 221 niveles.
###Tratamiento de observaciones NA
Ahora veremos si existen datos vacíos en la data con la función sapply() y para buscar los datos vacíos en se utiliza is.na().
## id name
## 0 0
## host_id host_name
## 0 0
## neighbourhood_group neighbourhood
## 0 0
## latitude longitude
## 0 0
## room_type price
## 0 0
## minimum_nights number_of_reviews
## 0 0
## last_review reviews_per_month
## 0 10052
## calculated_host_listings_count availability_365
## 0 0Observamos que en las variables reviews_per_month posee 10052 datos vacíos y para ver los datos vacíos es lo mismo, pero con is.null().
## id name
## 0 0
## host_id host_name
## 0 0
## neighbourhood_group neighbourhood
## 0 0
## latitude longitude
## 0 0
## room_type price
## 0 0
## minimum_nights number_of_reviews
## 0 0
## last_review reviews_per_month
## 0 0
## calculated_host_listings_count availability_365
## 0 0No existe datos nulos en la data como se puede observar. Ahora para eliminar los datos vacíos observados anteriormente.
5.3.2.1 Eliminar las observaciones NA en r studio
Veremos si las observaciones fueron eliminadas.
## [1] 388435.3.3 Exploración de las variables
Realizaremos la exploración de la variable ID, lo primero que veremos es si los datos de esta variable son datos únicos, para ello crearemos la data ID y usaremos la función select() que nos ayudara seleccionar la base y las variables que deseamos observar, y además utilizaremos la función unique() para ver si son únicas en su valor.
## [1] 38843La data tiene 48895 datos y la columna ID igual por lo que no existen datos repetidos. Con la variable name veremos si existen datos vacíos en la data y cual es ID de estos datos vacíos.
## [1] id name
## <0 rows> (or 0-length row.names)No existe datos vacíos. Ahora siguiéremos saber el nombre especifico de un ID, usaremos el mismo código anterior, pero en la función filter() colocamos ID == que representa el igual y el ID que deseamos buscar en este caso es el 2232600.
## id name
## 1 22326005.3.3.1 Remplazar observaciones
Como observamos no existe nombre, esto demuestra que a veces es bueno realizar más de una revisión. Para solucionar estos problemas remplazaremos los datos en blanco por No .
## Warning in `[<-.factor`(`*tmp*`, airbnb$name == "", value =
## structure(c(12573L, : invalid factor level, NA generated## id name
## 1 2232600 <NA>
## 2 4209595 <NA>
## 3 4370230 <NA>
## 4 9325951 <NA>
## 5 10052289 <NA>
## 6 22275821 <NA>Antes de eliminarlo tenemos que ver si estos datos son relevantes para nuestro estudio y si esas variables la utilizaremos más adelante.
## Warning in `[<-.factor`(`*tmp*`, airbnb$host_name == "", value =
## structure(c(4997L, : invalid factor level, NA generatedAhora veremos la variable neighbourhood_group y cuales son los niveles de esta variable.
## neighbourhood_group
## 1 Brooklyn
## 2 Manhattan
## 47 Queens
## 170 Staten Island
## 172 BronxCon la variable price veremos el promedio, máximo, varianza y mínimo.
## mean variance min max
## 1 142.3179 38787.58 0 10000El mínimo es 0 por que existen hospedaje con “precio 0” esto es ilógico para una empresa por lo que se busca identificar cuáles son estos datos.
## id price
## 1 18750597 0
## 2 20333471 0
## 3 20523843 0
## 4 20608117 0
## 5 20624541 0
## 6 20639628 0
## 7 20639792 0
## 8 20639914 0
## 9 21291569 0
## 10 21304320 0Son 10 datos y como los ID son datos únicos se entiende que estos datos no se repitieran. esta columna es relevante por lo que se elimina los 11 datos nulos.
airbnb <-airbnb [airbnb$price!="0",] #elimina los 0
summarise(airbnb, mean = mean(price), variance = var(price), min = min(price), max = max(price))## mean variance min max
## 1 142.3546 38792.35 10 10000Con la variable minimum_nights.
## mean variance min max
## 1 5.867561 302.2754 1 1250Existen máximos con más de 365 días por lo que se determina que no es coherente en consecuencia se eliminan las celdas mayores a 365.
## [1] 6cuando queremos eliminar observaciones especificas utilizamos el siguiente código.
Se eliminan para no afectar la data y verificamos.
## mean variance min max
## 1 5.74953 195.6422 1 365Ahora veremos la variable number_of_reviews.
## mean variance min max
## 1 29.29801 2322.392 1 629